
Eric Brachmann
I am a senior staff scientist at Niantic Spatial, working on the Visual Positioning System (VPS). I work at the intersection of machine learning and computer vision, 3D vision in particular. My research revolves around topics such as visual relocalisation, pose estimation, end-to-end learning, robust parameter estimation and feature matching.
I publish my research in the top conferences in computer vision where I am also active as area chair and reviewer with several outstanding reviewer mentions. I co-organized several tutorials and workshops on visual relocalisation, object pose estimation and robust parameter estimation.
E-Mail Google Scholar Bluesky LinkedIn CVAxel Barroso-Laguna, Tommaso Cavallari, Victor Adrian Prisacariu,
TL;DR: FastForward - Efficient visual relocalization without building structured 3D maps. Relative pose between query and a set of retrieved mapping images.
arXiv project page, Jamie Wynn, Shuai Chen, Tommaso Cavallari, Áron Monszpart, Daniyar Turmukhambetov, Victor Adrian Prisacariu
TL;DR: self-supervised ACE = learning-based structure-from-motion, needs no pose priors, works on unordered image sets, efficiently handles thousands of images.
arXiv project page code videoAxel Barroso-Laguna, Sowmya Munukutla, Victor Adrian Prisacariu,
TL;DR: MicKey, a method that regresses and matches scale-metric 3D key points, trained end-to-end using differentiable RANSAC
arXiv project page codeEduardo Arnold, Jamie Wynn, Sara Vicente, Guillermo Garcia-Hernando, Aron Monszpart, Victor Prisacariu, Daniyar Turmukhambetov,
TL;DR: only one mapping image and one query, dataset with multiple hundred outdoor scenes, benchmark and online leaderboard
arXiv supplement project page code dataset videoAritra Bhowmik, Stefan Gumhold, Carsten Rother,
TL;DR: refine SuperPoint end-to-end for relative pose estimation, gradients of feature matching wrt feature descriptors and key point heatmap
arXiv code video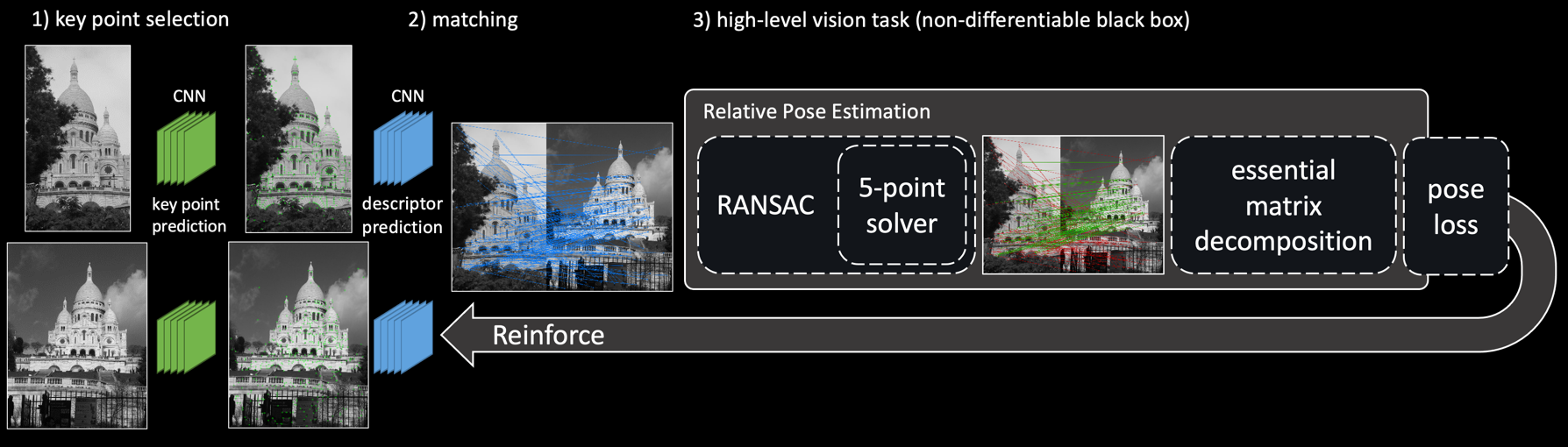
, Carsten Rother
TL;DR: NG-RANSAC + NG-DSAC, gradients of RANSAC-fitted model wrt quality of data points, applied to E/F matrix fitting, horizon line estimation and camera relocalization
arXiv project page F/E matrix code horizon line code relocalisation code videoTomas Hodan, Frank Michel, , Wadim Kehl, Anders Buch, Dirk Kraft, Bertram Drost, Joel Vidal, Stephan Ihrke , Xenophon Zabulis, Caner Sahin, Fabian Manhardt, Federico Tombari, Tae-Kyun Kim, Jiri Matas, Carsten Rother
TL;DR: de facto standard benchmark for instance pose estimation, unifying dataset formats and proposing evaluation metrics, ongoing competition with online leaderboard
arXiv project page
, Carsten Rother
TL;DR: DSAC++, first time training scene coordinate regression without depth, differentiable PnP
arXiv project page code video, Alexander Krull, Sebastian Nowozin, Jamie Shotton, Frank Michel, Stefan Gumhold, Carsten Rother
TL;DR: gradients of a RANSAC-fitted model wrt the coordinates of the input points, using policy gradient on discrete hypothesis selection
arXiv project page toy code relocalisation code video, Alexander Krull, Frank Michel, Stefan Gumhold, Jamie Shotton, Carsten Rother
TL;DR: introduces dense image-to-object correspondences as a learnable intermediate representation, introduced the LINEMOD-Occlusion dataset
paper supplement project page dataset video 1 video 2Leonard Bruns, Axel Barroso-Laguna, Tommaso Cavallari, Áron Monszpart, Sowmya Munukutla, Victor Adrian Prisacariu,
TL;DR: disentangle coordinate regression and latent map representation, pre-train the regressor on thousands of scenes to generalize from mapping data to difficult query images.
arXiv project page code videoWenjing Bian, Axel Barroso-Laguna, Tommaso Cavallari, Victor Adrian Prisacariu,
TL;DR: Combine ACE and ACE0 with various priors to stabilize reconstruction: leveraging RGB-D data if available, regularizing the scene-level depth distribution, utilize a 3D generative model trained on successful reconstructions.
arXiv project page code videoAxel Barroso-Laguna, Tommaso Cavallari, Victor Adrian Prisacariu,
TL;DR: FastForward - Efficient visual relocalization without building structured 3D maps. Relative pose between query and a set of retrieved mapping images.
arXiv project pageVan Nguyen Nguyen, Stephen Tyree, Andrew Guo, Mederic Fourmy, Anas Gouda, Taeyeop Lee, Sungphill Moon, Hyeontae Son, Lukas Ranftl, Jonathan Tremblay, , Bertram Drost, Vincent Lepetit, Carsten Rother, Stan Birchfield, Jiri Matas, Yann Labbe, Martin Sundermeyer, Tomas Hodan
TL;DR: results of BOP challenge 2024, significant progress for model-based pose localization of unseen objects, community has not yet signed on to the new task of model-free pose detection.
arXiv project page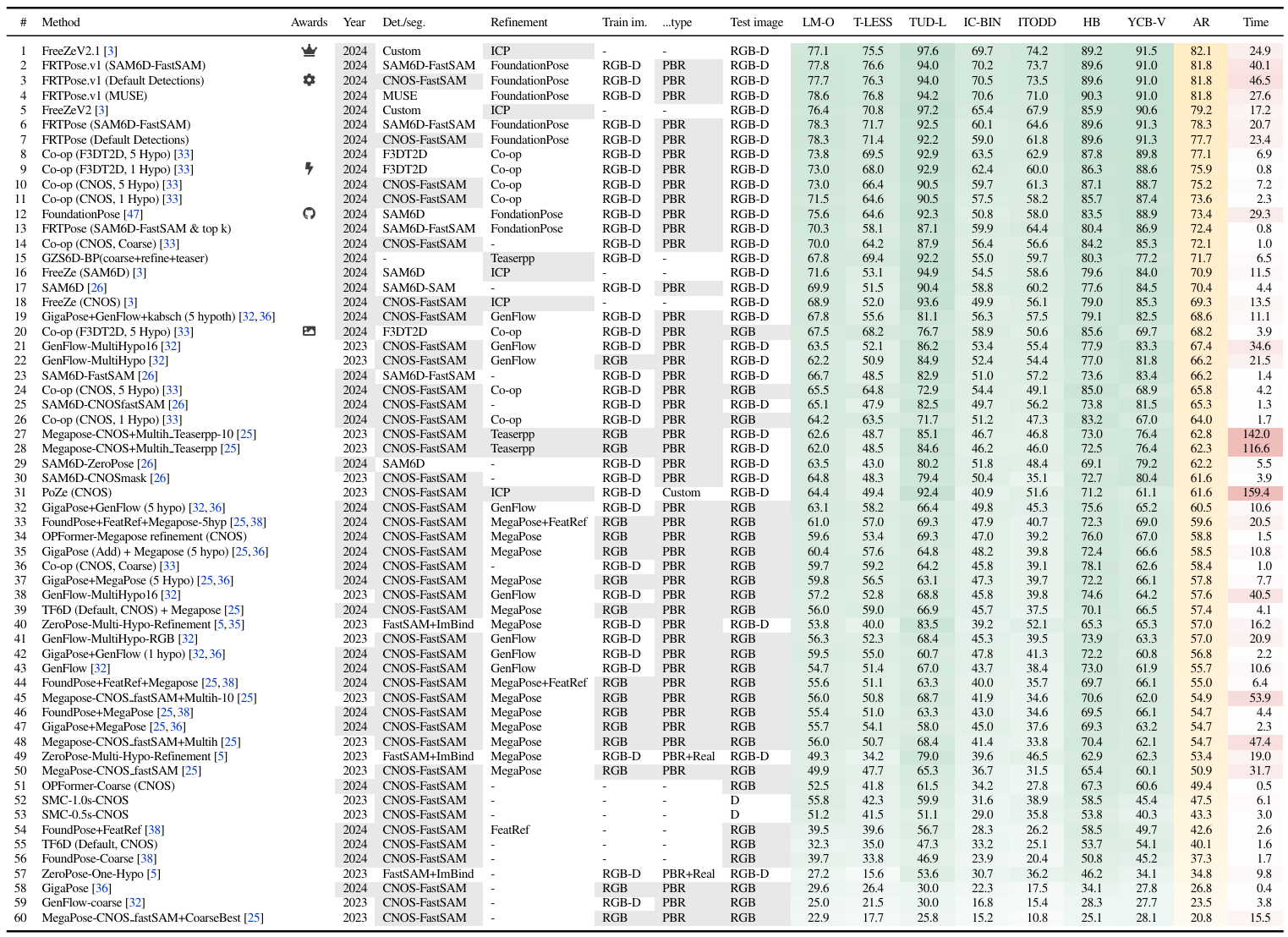
, Jamie Wynn, Shuai Chen, Tommaso Cavallari, Áron Monszpart, Daniyar Turmukhambetov, Victor Adrian Prisacariu
TL;DR: self-supervised ACE = learning-based structure-from-motion, needs no pose priors, works on unordered image sets, efficiently handles thousands of images.
arXiv project page code videoShuai Chen, Tommaso Cavallari, Victor Adrian Prisacariu,
TL;DR: marepo, a scene-agnostic absolute pose regression transformer on top of a scene-specific ACE map representation, on-par with structure-based relocalizers in terms of accuracy and mapping time
arXiv project page codeAxel Barroso-Laguna, Sowmya Munukutla, Victor Adrian Prisacariu,
TL;DR: MicKey, a method that regresses and matches scale-metric 3D key points, trained end-to-end using differentiable RANSAC
arXiv project page codeTomas Hodan, Martin Sundermeyer, Yann Labbe, Van Nguyen Nguyen, Gu Wang, , Bertram Drost, Vincent Lepetit, Carsten Rother, Jiri Matas
TL;DR: results of BOP challenge 2023, accuracy is excellent if objects are known in advance, for unseen objects, still good but slow
arXiv project page video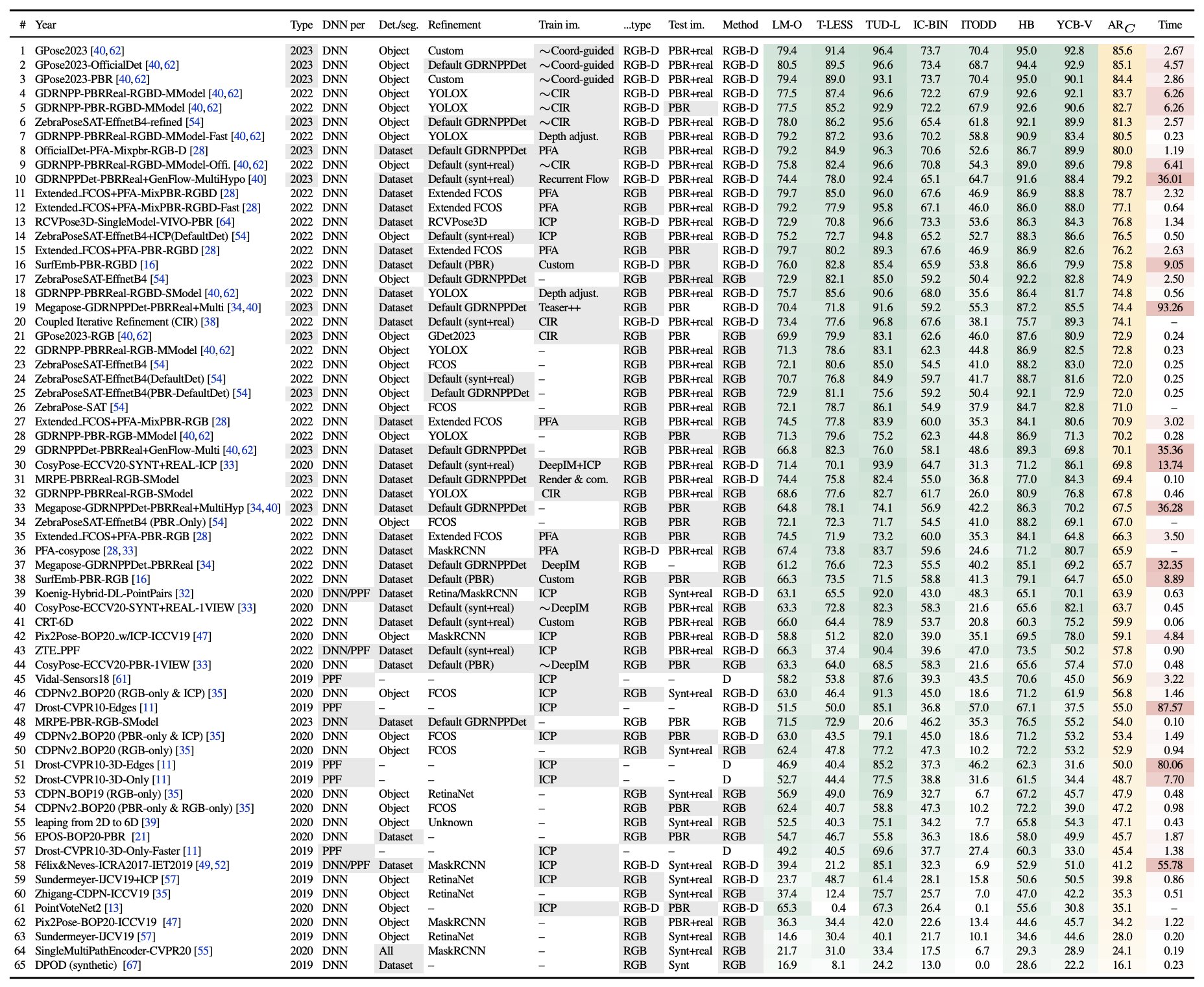
Martin Sundermeyer, Tomas Hodan, Yann Labbe, Gu Wang, , Bertram Drost, Carsten Rother, Jiri Matas
TL;DR: results of BOP challenge 2022, deep neural networks beat everything else
arXiv project page video 1 video 2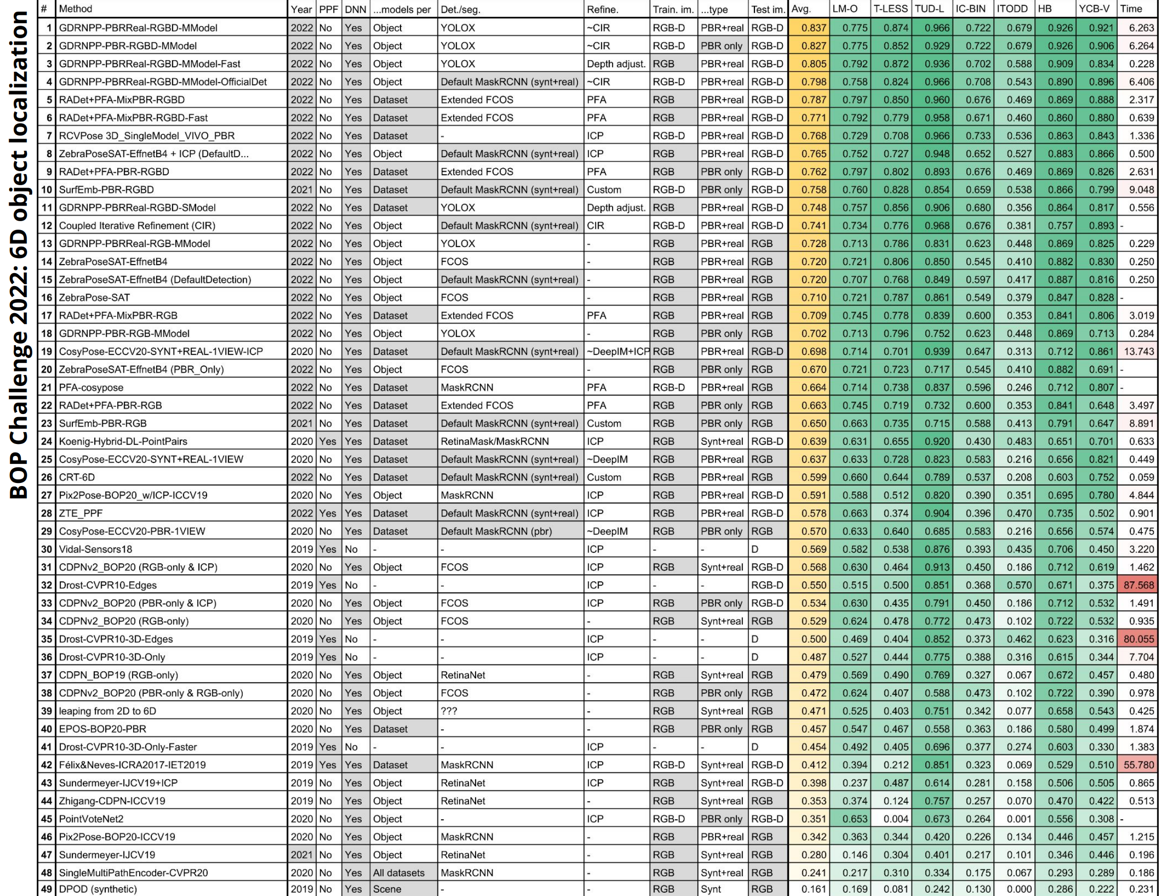
Eduardo Arnold, Jamie Wynn, Sara Vicente, Guillermo Garcia-Hernando, Aron Monszpart, Victor Prisacariu, Daniyar Turmukhambetov,
TL;DR: only one mapping image and one query, dataset with multiple hundred outdoor scenes, benchmark and online leaderboard
arXiv supplement project page code dataset videoKarren Yang, Michael Firman, , Clement Godard
TL;DR: camera pose by echolocation, relative pose / absolute pose / image retrieval, vision is more accurate but sound helps when vision fails
paper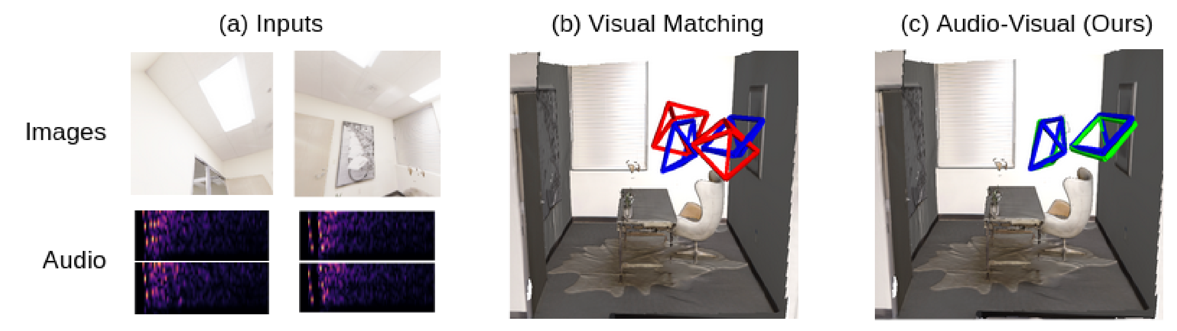
Tomas Hodan, Martin Sundermeyer, Bertram Drost, Yann Labbe, , Frank Michel, Carsten Rother, Jiri Matas
TL;DR: results of BOP challenge 2020, deep neural networks on par with point pair features
arXiv project page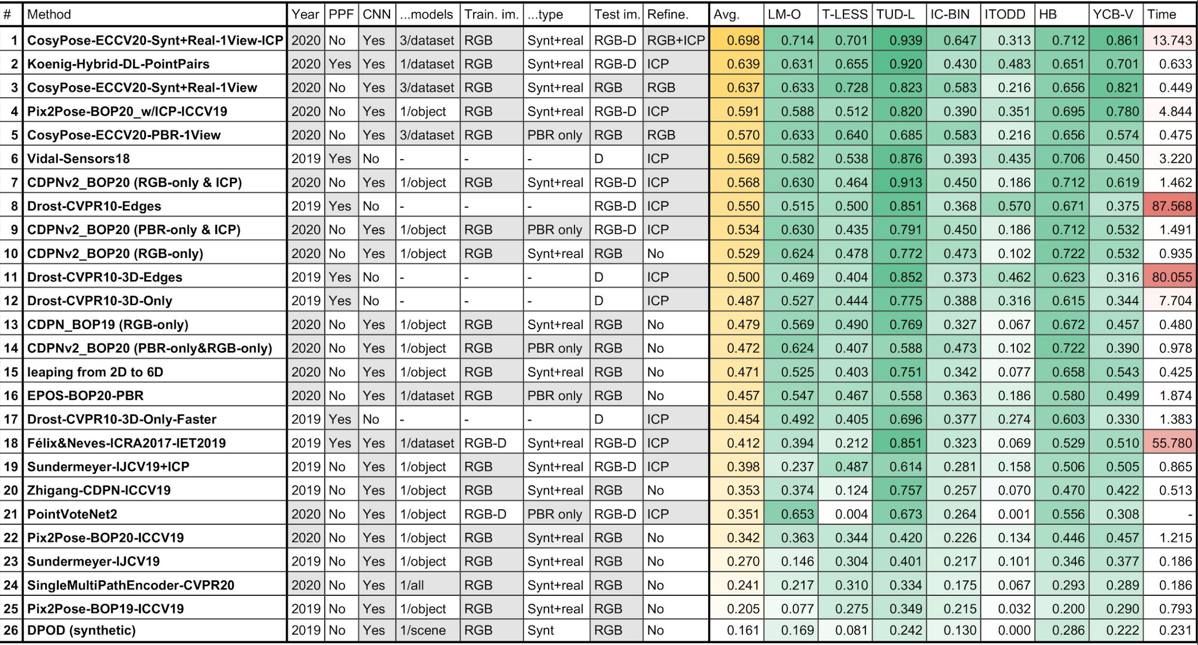
Aritra Bhowmik, Stefan Gumhold, Carsten Rother,
TL;DR: refine SuperPoint end-to-end for relative pose estimation, gradients of feature matching wrt feature descriptors and key point heatmap
arXiv code video
, Carsten Rother
TL;DR: ESAC, end-to-end learning of mixture-of-experts and RANSAC, large scale scene coordinate regression
arXiv project page code video
, Carsten Rother
TL;DR: NG-RANSAC + NG-DSAC, gradients of RANSAC-fitted model wrt quality of data points, applied to E/F matrix fitting, horizon line estimation and camera relocalization
arXiv project page F/E matrix code horizon line code relocalisation code videoOmid Hosseini Jafari, Siva Karthik Mustikovela, Karl Pertsch, , Carsten Rother
TL;DR: instance segmentation + deep object coordinate prediction
arXiv
Tomas Hodan, Frank Michel, , Wadim Kehl, Anders Buch, Dirk Kraft, Bertram Drost, Joel Vidal, Stephan Ihrke , Xenophon Zabulis, Caner Sahin, Fabian Manhardt, Federico Tombari, Tae-Kyun Kim, Jiri Matas, Carsten Rother
TL;DR: de facto standard benchmark for instance pose estimation, unifying dataset formats and proposing evaluation metrics, ongoing competition with online leaderboard
arXiv project page
TL;DR: summary of my work prior to 2018, learning object and scene coordinate regression using random forests and neural networks
thesis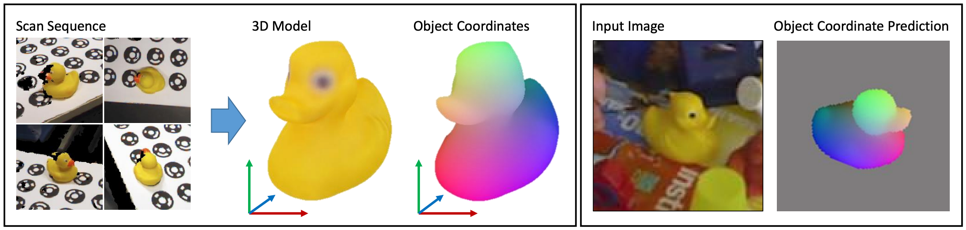
, Carsten Rother
TL;DR: DSAC++, first time training scene coordinate regression without depth, differentiable PnP
arXiv project page code video, Alexander Krull, Sebastian Nowozin, Jamie Shotton, Frank Michel, Stefan Gumhold, Carsten Rother
TL;DR: gradients of a RANSAC-fitted model wrt the coordinates of the input points, using policy gradient on discrete hypothesis selection
arXiv project page toy code relocalisation code videoFrank Michel, Alexander Kirillov, , Alexander Krull, Stefan Gumhold, Bogdan Savchynskyy, Carsten Rother
TL;DR: find pose inlier correspondences by optimizing the energy in a graphical model
arXiv project page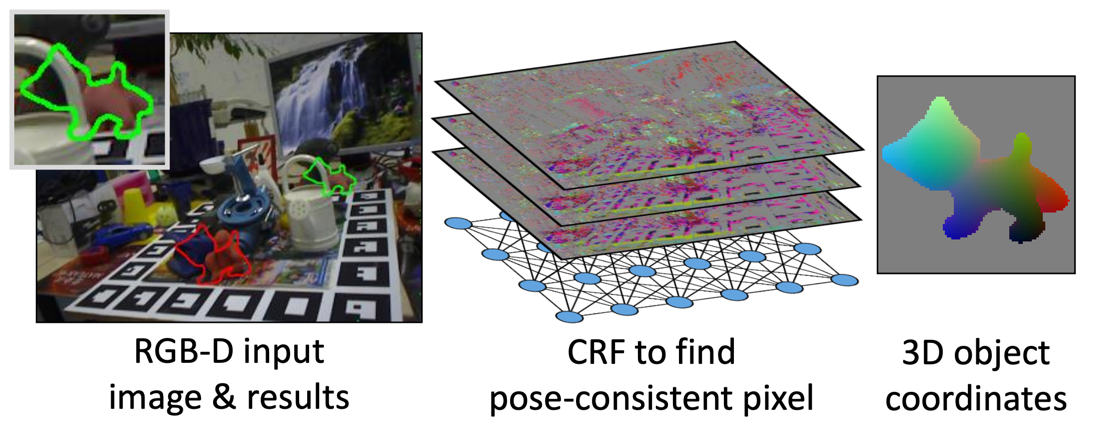
Alexander Krull, , Sebastian Nowozin, Frank Michel, Jamie Shotton, Carsten Rother
TL;DR: an RL agent chooses which RANSAC hypothesis to refine next
arXiv project page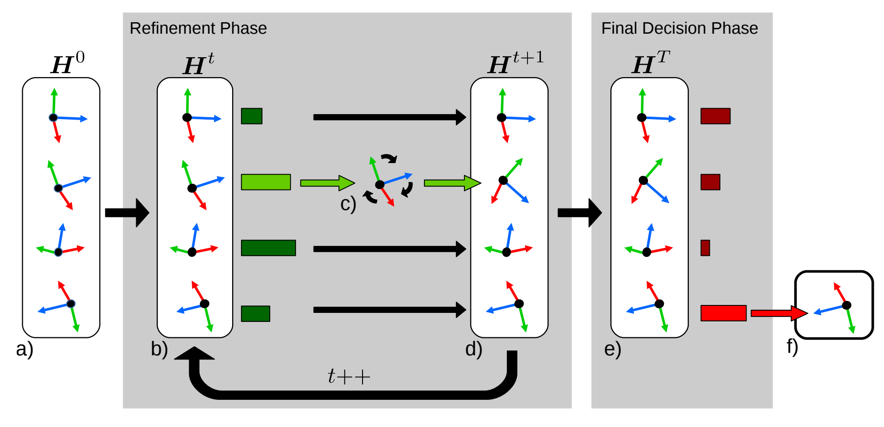
Daniela Massiceti, Alexander Krull, , Carsten Rother, Philip H.S. Torr
TL;DR: mapping of random forests to NNs for optimization, and back again for efficiency
arXiv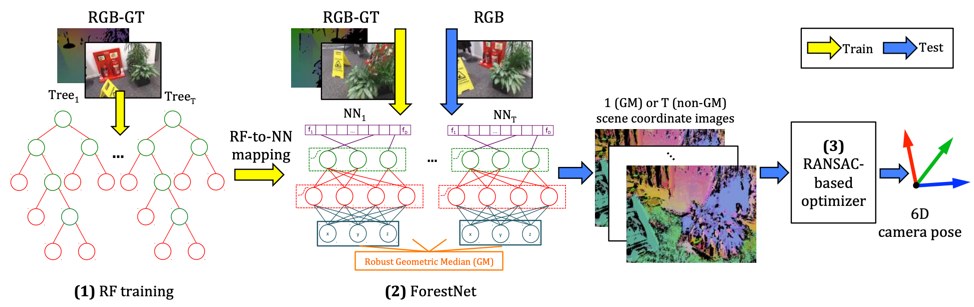
, Frank Michel, Alexander Krull, Michael Ying Yang, Stefan Gumhold, Carsten Rother
TL;DR: first object/scene coordinate regression system for RGB, predict correspondence distributions and search for max likelihood pose
paper supplement project page videoAlexander Krull, , Frank Michel, Michael Ying Yang, Stefan Gumhold, Carsten Rother
TL;DR: substitute inlier counting pose score with a CNN that compares input image and renderings, trained via max likelihood
paper supplement project page video
Frank Michel, Alexander Krull, , Michael Ying Yang, Stefan Gumhold, Carsten Rother
TL;DR: only n+2 correspondences are needed to estimate pose of n-jointed objects
paper conference page project page
Alexander Krull, Frank Michel, , Stefan Gumhold, Stephan Ihrke, Carsten Rother
TL;DR: combines RANSAC-based hypothesis sampling with particle filter for real-time pose tracking
paper supplement project page video 1 video 2, Alexander Krull, Frank Michel, Stefan Gumhold, Jamie Shotton, Carsten Rother
TL;DR: introduces dense image-to-object correspondences as a learnable intermediate representation, introduced the LINEMOD-Occlusion dataset
paper supplement project page dataset video 1 video 2, Marcel Spehr, Stefan Gumhold
TL;DR: propagate visual words along image web edges to make a BoW image descriptors more robust
paper
, Gero Dittmann, Klaus-Dieter Schubert
TL;DR: an authentication scheme for company intranets where you may want to trade security for simplicity
paper